C++中的内联函数¶
C++提供了内联函数来减少函数调用开销。内联函数是在调用时展开的函数。当调用内联函数时,内联函数的整个代码会在内联函数调用点插入或替换。这种替换由C++编译器在编译时执行。如果内联函数很小,它可以提高效率。
语法:
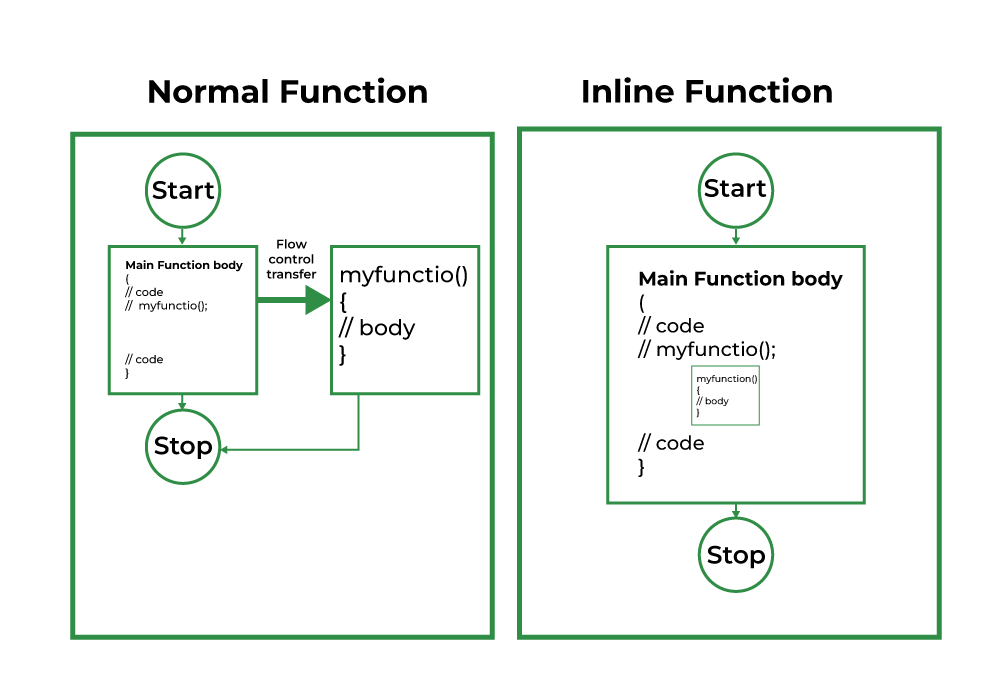
请记住,内联只是对编译器的一个请求,而不是命令。编译器可以忽略内联请求。
编译器在这种情况下可能不会执行内联:
- 如果函数包含一个循环。(for、while和do-while)
- 如果函数包含静态变量。
- 如果函数是递归的。
- 如果函数的返回类型不是void,并且函数体中不存在return语句。
- 如果函数包含switch或goto语句。
为什么使用内联函数?¶
当程序执行函数调用指令时,CPU存储函数调用之后指令的内存地址,将函数的参数复制到堆栈上,最后将控制权转移到指定的函数。然后CPU执行函数代码,将函数的返回值存储在预定义的内存位置/寄存器中,并将控制权返回到调用函数。如果函数的执行时间小于从调用函数到被调用函数(被调用者)的切换时间,这可能会成为开销。
对于大型和/或执行复杂任务的函数,函数调用的开销通常与函数运行所需的时间相比微不足道。然而,对于小型、常用的函数,进行函数调用所需的时间通常比实际执行函数代码所需的时间多得多。这种开销发生在小型函数上,因为小型函数的执行时间小于切换时间。
内联函数的优点:¶
- 不会发生函数调用开销。
- 它还节省了调用函数时在堆栈上推/弹变量的开销。
- 它还节省了从函数返回调用的开销。
- 当你内联一个函数时,你可以使编译器对函数体进行特定于上下文的优化。对于普通函数调用,这种优化是不可能的。通过考虑调用上下文和被调用上下文的流程,可以获得其他优化。
- 对于嵌入式系统,内联函数可能有用(如果它很小),因为内联可以比函数调用前导和返回生成更少的代码。
内联函数的缺点:¶
-
内联函数添加的变量消耗额外的寄存器,如果在内联函数之后使用的变量数量增加,它们可能会在寄存器变量资源利用上产生开销。这意味着当内联函数体在函数调用点被替换时,函数使用的变量总数也会被插入。因此,用于变量的寄存器数量也会增加。因此,如果内联函数后变量数量急剧增加,那么它肯定会引起寄存器利用的开销。
-
如果你使用太多内联函数,二进制可执行文件的大小会变大,因为代码的重复。
-
过多的内联也可能降低指令缓存命中率,从而降低从缓存内存到主内存的指令获取速度。
-
如果有人更改了内联函数中的代码,那么所有调用位置都必须重新编译,因为编译器需要再次替换所有代码以反映更改,否则它将继续使用旧功能。
-
内联函数对于许多嵌入式系统可能没有用处。因为在嵌入式系统中,代码大小比速度更重要。
-
内联函数可能会导致抖动,因为内联可能会增加二进制可执行文件的大小。内存中的抖动会导致计算机性能下降。以下程序演示了内联函数的使用。
示例:
#include <iostream>
using namespace std;
inline int cube(int s) { return s * s * s; }
int main()
{
cout << "The cube of 3 is: " << cube(3) << "\n";
return 0;
}
输出
内联函数和类¶
在类中定义内联函数也是可能的。事实上,在类中定义的所有函数都是隐式内联的。因此,内联函数的所有限制也适用于此。如果你需要在类中显式声明内联函数,只需在类中声明函数,并在类外使用inline关键字定义它。
语法:
class S
{
public:
inline int square(int s) // redundant use of inline
{
// this function is automatically inline
// function body
}
};
上述风格被认为是糟糕的编程风格。最佳编程风格是在类中只编写函数的原型,并在函数定义中将其指定为内联。
例如:
class S
{
public:
int square(int s); // declare the function
};
inline int S::square(int s) // use inline prefix
{
}
示例:
// C++ Program to demonstrate inline functions and classes
#include <iostream>
using namespace std;
class operation {
int a, b, add, sub, mul;
float div;
public:
void get();
void sum();
void difference();
void product();
void division();
};
inline void operation ::get()
{
cout << "Enter first value:";
cin >> a;
cout << "Enter second value:";
cin >> b;
}
inline void operation ::sum()
{
add = a + b;
cout << "Addition of two numbers: " << a + b << "\n";
}
inline void operation ::difference()
{
sub = a - b;
cout << "Difference of two numbers: " << a - b << "\n";
}
inline void operation ::product()
{
mul = a * b;
cout << "Product of two numbers: " << a * b << "\n";
}
inline void operation ::division()
{
div = a / b;
cout << "Division of two numbers: " << a / b << "\n";
}
int main()
{
cout << "Program using inline function\n";
operation s;
s.get();
s.sum();
s.difference();
s.product();
s.division();
return 0;
}
Output:
Enter first value: 45
Enter second value: 15
Addition of two numbers: 60
Difference of two numbers: 30
Product of two numbers: 675
Division of two numbers: 3
宏有什么问题?¶
宏有什么问题? 熟悉C语言的读者知道,C语言使用宏。预处理器将宏调用直接替换为宏代码。建议始终使用内联函数而不是宏。根据C++的创造者Bjarne Stroustrup博士的说法,宏在C++中几乎永远不是必要的,而且它们容易出错。在C++中使用宏有一些问题。宏无法访问类的私有成员。宏看起来像函数调用,但实际上不是。
示例:
// C++ Program to demonstrate working of macro
#include <iostream>
using namespace std;
class S {
int m;
public:
// error
#define MAC(S::m)
};
输出:
C++编译器检查内联函数的参数类型,并正确执行必要的转换。预处理器宏无法做到这一点。另一件事是,宏由预处理器管理,而内联函数由C++编译器管理。记住:在类中定义的所有函数都是隐式内联的,C++编译器将执行这些函数的内联调用,但如果函数是虚函数,C++编译器无法执行内联。原因是虚函数的调用在运行时而不是编译时解析。虚意味着等到运行时,而内联意味着在编译时,如果编译器不知道将调用哪个函数,它如何执行内联?另一件要记住的事情是,只有在函数调用所花费的时间比函数体执行时间多时,使函数内联才有用。
一个内联函数完全没有效果的例子:
上述函数相对需要很长时间才能执行。通常,执行输入输出(I/O)操作的函数不应该定义为内联,因为它花费了相当多的时间。从技术上讲,show()函数的内联价值有限,因为I/O语句所花费的时间远远超过函数调用的开销。根据你使用的编译器,如果函数没有内联展开,编译器可能会向你显示警告。
像Java和C#这样的编程语言不支持内联函数。但在Java中,当调用小型的final方法时,编译器可以执行内联,因为final方法不能被子类覆盖,并且对final方法的调用在编译时解析。
在C#中,JIT编译器也可以通过内联小型函数调用(如在循环中调用时替换小型函数的函数体)来优化代码。最后要记住的是,内联函数是C++的一个有价值的功能。适当使用内联函数可以提高性能,但如果内联函数被随意使用,它们可能无法提供更好的结果。换句话说,不要期望程序的性能更好。不要将每个函数都内联。最好将内联函数保持得尽可能小。