使用ARIMA进行时间序列预测¶
在上一节课中,你已经了解了一些时间序列预测的知识,并加载了一个展示一段时间内电力负荷波动的数据集。

点击上方图片观看视频:ARIMA模型简介。示例使用R语言完成,但概念具有通用性。
课前小测¶
引言¶
在本节课中,你将学习一种特定的建模方法——ARIMA:自回归积分移动平均模型。ARIMA模型特别适合拟合具有非平稳性的数据。
基本概念¶
要使用ARIMA,你需要了解一些概念:
-
平稳性。从统计学角度来看,平稳性指的是数据的分布在时间推移时保持不变。而非平稳数据则会因趋势而呈现波动,必须经过转换才能进行分析。例如,季节性可能会导致数据出现波动,这可以通过“季节性差分”过程来消除。
-
差分。从统计学角度来看,数据差分指的是通过消除非恒定趋势,将非平稳数据转换为平稳数据的过程。“差分消除了时间序列水平的变化,消除了趋势和季节性,从而稳定了时间序列的均值。”Shixiong等人的论文
时间序列背景下的ARIMA¶
让我们拆解ARIMA的各个部分,以更好地理解它如何帮助我们对时间序列进行建模并做出预测。
-
AR(自回归,AutoRegressive):顾名思义,自回归模型会回顾过去的时间,分析数据中的先前值并对其进行假设。这些先前值被称为“滞后值(lags)”。例如,显示铅笔月度销量的数据中,每个月的销售总额会被视为数据集中的“演化变量”。该模型的构建方式是“将感兴趣的演化变量对其自身的滞后(即先前)值进行回归”。维基百科
-
I(积分,Integrated):与类似的“ARMA”模型不同,ARIMA中的“I”指的是其积分特性。当应用差分步骤以消除非平稳性时,数据就被“积分”了。
-
MA(移动平均,Moving Average):该模型的移动平均特性指的是通过观察滞后值的当前和过去值来确定输出变量。
总而言之:ARIMA用于使模型尽可能紧密地拟合时间序列数据的特殊形式。
练习 - 构建ARIMA模型¶
打开本节课的/working文件夹,找到notebook.ipynb文件。
-
运行笔记本以加载
statsmodelsPython库;这是ARIMA模型所需的库。 -
加载必要的库
-
现在,加载更多对绘制数据有用的库:
Pythonimport os import warnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt import math from pandas.plotting import autocorrelation_plot from statsmodels.tsa.statespace.sarimax import SARIMAX from sklearn.preprocessing import MinMaxScaler from common.utils import load_data, mape from IPython.display import Image %matplotlib inline pd.options.display.float_format = '{:,.2f}'.format np.set_printoptions(precision=2) warnings.filterwarnings("ignore") # 指定忽略警告消息 -
将
/data/energy.csv文件中的数据加载到Pandas数据框中并查看: -
绘制2012年1月至2014年12月的所有可用电力数据。由于我们在上一课中已经见过这些数据,所以这里不会有什么意外:
Pythonenergy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()现在,让我们来构建一个模型!
创建训练集和测试集¶
现在数据已加载,你可以将其分为训练集和测试集。你将在训练集上训练模型。与往常一样,模型训练完成后,你将使用测试集评估其准确性。你需要确保测试集覆盖的时间段晚于训练集,以确保模型不会从未来的时间段获取信息。
-
将2014年9月1日至10月31日这两个月的时间分配给训练集。测试集将包含2014年11月1日至12月31日这两个月的时间:
由于这些数据反映了每日的能源消耗,因此存在很强的季节性模式,但消耗量与最近几天的消耗量最为相似。
-
可视化差异:
Pythonenergy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \ .join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \ .plot(y=['train', 'test'], figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()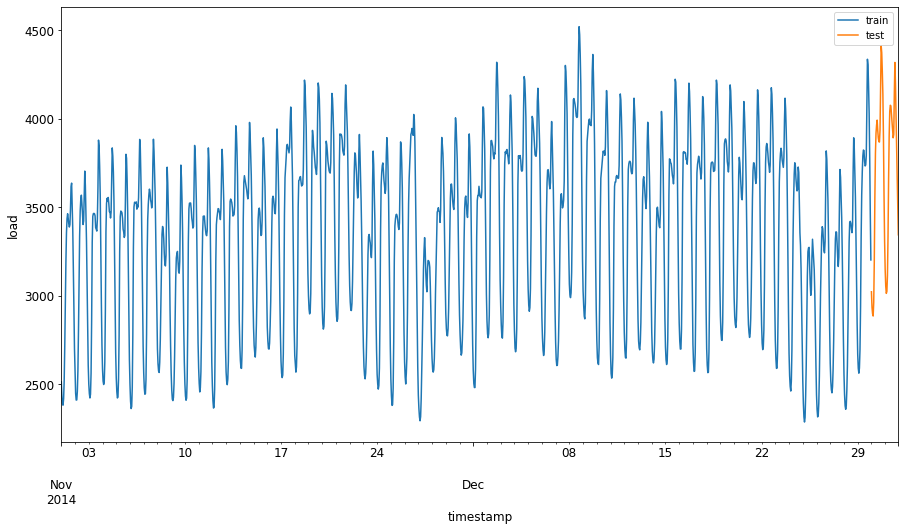
因此,使用相对较小的时间窗口来训练数据应该就足够了。
注意:由于我们用于拟合ARIMA模型的函数在拟合过程中使用样本内验证,因此我们将省略验证数据。
准备训练数据¶
现在,你需要通过对数据进行过滤和缩放来准备训练数据。过滤数据集以仅包含所需的时间段和列,并进行缩放以确保数据投影到0到1的区间内。
-
过滤原始数据集,使其仅包含上述每个集合的时间段,且只包含所需的“load”列和日期:
Pythontrain = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']] test = energy.copy()[energy.index >= test_start_dt][['load']] print('训练数据形状:', train.shape) print('测试数据形状:', test.shape)你可以看到数据的形状:
-
将数据缩放到(0, 1)范围内。
-
可视化原始数据与缩放后的数据:
Pythonenergy[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']].rename(columns={'load':'original load'}).plot.hist(bins=100, fontsize=12) train.rename(columns={'load':'scaled load'}).plot.hist(bins=100, fontsize=12) plt.show()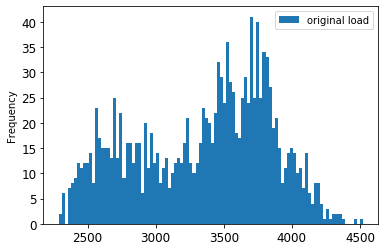
原始数据
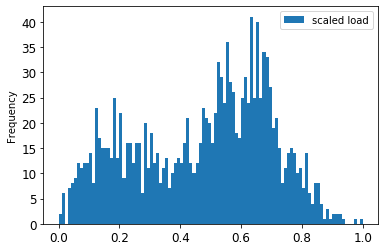
缩放后的数据
-
既然你已经校准了缩放数据,就可以对测试数据进行缩放了:
实现ARIMA模型¶
现在是实现ARIMA模型的时候了!你将使用之前安装的statsmodels库。
现在你需要遵循以下几个步骤:
- 通过调用
SARIMAX()函数定义模型,并传入模型参数:p、d和q参数,以及P、D和Q参数。 - 通过调用fit()函数为训练数据准备模型。
- 调用
forecast()函数进行预测,并指定预测的步数(horizon)。
所有这些参数都是做什么用的?在ARIMA模型中,有3个参数用于帮助对时间序列的主要方面进行建模:季节性、趋势和噪声。这些参数是:
p:与模型的自回归部分相关的参数,它结合了过去的值。 d:与模型的积分部分相关的参数,它影响对时间序列应用的差分量(还记得上面提到的差分吗?)。 q:与模型的移动平均部分相关的参数。
注意:如果你的数据具有季节性特征——这个数据集确实有——我们使用季节性ARIMA模型(SARIMA)。在这种情况下,你需要使用另一组参数:
P、D和Q,它们描述的关联与p、d和q相同,但对应于模型的季节性成分。
-
首先设置你偏好的预测范围值。让我们尝试3小时:
为ARIMA模型的参数选择最佳值可能具有挑战性,因为这在一定程度上带有主观性且耗时。你可以考虑使用
pyramid库中的auto_arima()函数。 -
现在先尝试一些手动选择来找到一个好的模型。
Pythonorder = (4, 1, 0) seasonal_order = (1, 1, 0, 24) model = SARIMAX(endog=train, order=order, seasonal_order=seasonal_order) results = model.fit() print(results.summary())会打印出结果表格。
你已经构建了第一个模型!现在我们需要找到一种方法来评估它。
评估你的模型¶
要评估你的模型,可以使用所谓的“滚动向前验证(walk forward validation)”。在实际应用中,每当有新数据可用时,时间序列模型都会重新训练。这能让模型在每个时间步都做出最佳预测。
使用这种技术时,从时间序列的起始处开始,在训练数据集上训练模型。然后对下一个时间步进行预测。将预测结果与已知值进行评估。随后,扩展训练集以包含该已知值,并重复此过程。
注意:为了更高效地训练,你应该保持训练集窗口固定,这样每次向训练集添加新观测值时,就从集合的起始处移除一个观测值。
这个过程能更可靠地估计模型在实际应用中的表现。然而,其代价是需要创建大量模型,计算成本较高。如果数据量较小或模型较简单,这是可以接受的,但在大规模场景下可能会出现问题。
滚动向前验证是时间序列模型评估的黄金标准,建议在你自己的项目中使用。
-
首先,为每个预测范围步长创建一个测试数据点。
Pythontest_shifted = test.copy() for t in range(1, HORIZON+1): test_shifted['load+'+str(t)] = test_shifted['load'].shift(-t, freq='H') test_shifted = test_shifted.dropna(how='any') test_shifted.head(5)load load+1 load+2 2014-12-30 00:00:00 0.33 0.29 0.27 2014-12-30 01:00:00 0.29 0.27 0.27 2014-12-30 02:00:00 0.27 0.27 0.30 2014-12-30 03:00:00 0.27 0.30 0.41 2014-12-30 04:00:00 0.30 0.41 0.57 数据会根据其预测范围点进行水平偏移。
-
在循环中使用滑动窗口方法对测试数据进行预测,循环次数为测试数据的长度:
Python%%time training_window = 720 # 预留30天(720小时)用于训练 train_ts = train['load'] test_ts = test_shifted history = [x for x in train_ts] history = history[(-training_window):] predictions = list() order = (2, 1, 0) seasonal_order = (1, 1, 0, 24) for t in range(test_ts.shape[0]): model = SARIMAX(endog=history, order=order, seasonal_order=seasonal_order) model_fit = model.fit() yhat = model_fit.forecast(steps = HORIZON) predictions.append(yhat) obs = list(test_ts.iloc[t]) # 移动训练窗口 history.append(obs[0]) history.pop(0) print(test_ts.index[t]) print(t+1, ': 预测值 =', yhat, '期望值 =', obs)你可以看到训练过程:
Text Output2014-12-30 00:00:00 1 : 预测值 = [0.32 0.29 0.28] 期望值 = [0.32945389435989236, 0.2900626678603402, 0.2739480752014323] 2014-12-30 01:00:00 2 : 预测值 = [0.3 0.29 0.3 ] 期望值 = [0.2900626678603402, 0.2739480752014323, 0.26812891674127126] 2014-12-30 02:00:00 3 : 预测值 = [0.27 0.28 0.32] 期望值 = [0.2739480752014323, 0.26812891674127126, 0.3025962399283795] -
比较预测值与实际负荷:
Pythoneval_df = pd.DataFrame(predictions, columns=['t+'+str(t) for t in range(1, HORIZON+1)]) eval_df['timestamp'] = test.index[0:len(test.index)-HORIZON+1] eval_df = pd.melt(eval_df, id_vars='timestamp', value_name='prediction', var_name='h') eval_df['actual'] = np.array(np.transpose(test_ts)).ravel() eval_df[['prediction', 'actual']] = scaler.inverse_transform(eval_df[['prediction', 'actual']]) eval_df.head()输出 | | 时间戳 | h | 预测值 | 实际值 | | --- | --------------------- | ---- | --------- | --------- | | 0 | 2014-12-30 00:00:00 | t+1 | 3,008.74 | 3,023.00 | | 1 | 2014-12-30 01:00:00 | t+1 | 2,955.53 | 2,935.00 | | 2 | 2014-12-30 02:00:00 | t+1 | 2,900.17 | 2,899.00 | | 3 | 2014-12-30 03:00:00 | t+1 | 2,917.69 | 2,886.00 | | 4 | 2014-12-30 04:00:00 | t+1 | 2,946.99 | 2,963.00 |
观察每小时数据的预测值与实际负荷的对比。其准确性如何?
检查模型准确性¶
通过测试所有预测的平均绝对百分比误差(MAPE)来检查模型的准确性。
数学公式解析
MAPE 用于将预测准确性表示为一个比率,由上述公式定义。实际值t与预测值t的差值除以实际值t。“该计算中的绝对值对每个时间点的预测值求和,再除以拟合点的数量n。”维基百科
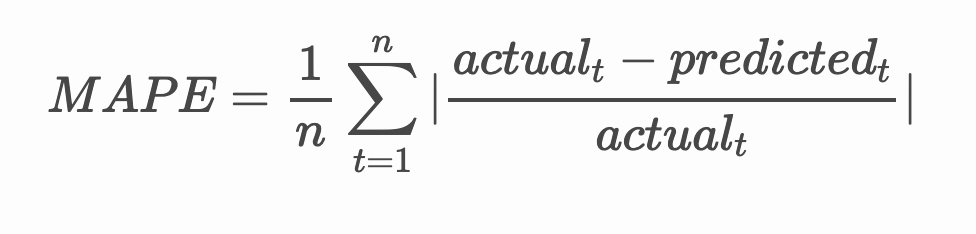
-
用代码表示该公式:
-
计算一步预测的MAPE:
Pythonprint('一步预测MAPE:', (mape(eval_df[eval_df['h'] == 't+1']['prediction'], eval_df[eval_df['h'] == 't+1']['actual']))*100, '%')一步预测MAPE: 0.5570581332313952 %
-
打印多步预测的MAPE:
数值越低越好:可以这样理解,MAPE为10意味着预测误差为10%。
-
但像往常一样,通过可视化方式查看这种准确性度量会更直观,所以让我们绘制图形:
Pythonif(HORIZON == 1): ## 绘制单步预测图 eval_df.plot(x='timestamp', y=['actual', 'prediction'], style=['r', 'b'], figsize=(15, 8)) else: ## 绘制多步预测图 plot_df = eval_df[(eval_df.h=='t+1')][['timestamp', 'actual']] for t in range(1, HORIZON+1): plot_df['t+'+str(t)] = eval_df[(eval_df.h=='t+'+str(t))]['prediction'].values fig = plt.figure(figsize=(15, 8)) ax = plt.plot(plot_df['timestamp'], plot_df['actual'], color='red', linewidth=4.0) ax = fig.add_subplot(111) for t in range(1, HORIZON+1): x = plot_df['timestamp'][(t-1):] y = plot_df['t+'+str(t)][0:len(x)] ax.plot(x, y, color='blue', linewidth=4*math.pow(.9,t), alpha=math.pow(0.8,t)) ax.legend(loc='best') plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()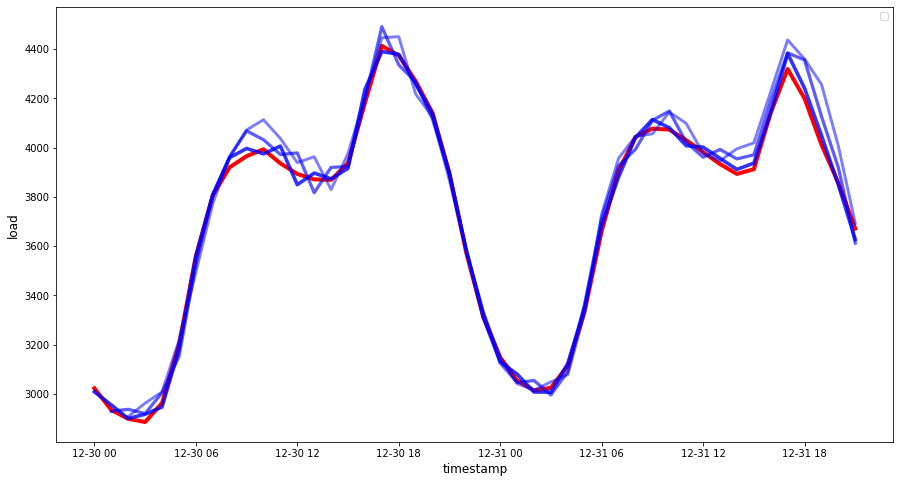
这是一张很棒的图表,显示模型具有良好的准确性。做得好!
?挑战¶
深入研究时间序列模型准确性的测试方法。本节课我们涉及了MAPE,但还有其他可用的方法吗?研究这些方法并进行注释。相关参考文档可查看此处
课后小测¶
复习与自学¶
本节课仅涉及了ARIMA时间序列预测的基础知识。花些时间深入学习,可以查看这个仓库及其各种模型类型,了解构建时间序列模型的其他方法。